
Vad innebär det att ett system har AI funktionalitet?
AI kan betyda att det är någon form av pryl, som kan utföra en uppgift som traditionellt har utförts av människor. Enligt den definitionen är all grad av automationsökning som gjorts sedan den flygande skytteln i starten av den industriella revolutionen en form av AI.
Men såklart tänker vi de senaste åren på vad som går att göra i mjukvara när AI diskuteras. Vad för framsteg har då skett som gjort att AI dyker upp överallt just nu? Det är för att fungerade tillämpningar av det gamla forskningsområdet ”Machine learning” sedan starten av 2010-talet lyckats utföra uppgifter inte tidigare möjligt på den tidens datorer.
Att Nvidia skapade CUDA 2006 var fundamentalt för att de här gamla teorierna äntligen skulle kunna testköras effektivt på tillräckligt snabb hårdvara. Vid den här tiden förstod då 17-årige Adam inte varför det skulle vara intressant att köra något annat än spel som Oblivion på grafikkortet…
Vad är CRUD?
A crud app is just a skin over a database. Traditionally this means the 5 core function – create, read one, read all, update and delete – with some auxiliary functions.
CRUD kan vara en simpel hemsida som har i uppgift att lagra ett fåtal sammanhörande domänobjekt. Kanske har samma information tidigare sammanställts i en Excel fil.
Utöver de vanliga operationerna på datan (Skapa, Hämta, Uppdatera, Ta bort) kanske även viss rättighetsstyrning behövs så endast vissa grupper av användare får till exempel ta bort en viss typ av objekt. I en sådan här applikation går inte en enda CPU cykel åt så länge inte någon människa läser eller modifierar datan. Skulle alla helt plötsligt sluta använda mjukvaran så skulle den aldrig igen utföra något arbete. Total stillhet infinner sig.
När blir en sådan här applikation AI?
Nästa steg i den naturliga utvecklingen av en sådan här ”app” är att tillföra mer och mer validering av den data som tillförs. När den tillförs.
Användaren skall varnas när ett fält missats fyllas i eller om något numeriskt värde är utanför det område verksamheten uppmärksammat skulle vara en bra regel att ha. Denna typ av invärdesvalideringar kan bli mer och mer avancerad desto längre man kommer från enkla datatypskontroller till ren affärslogik unikt anpassad för den aktuella verksamhetens nuvarande behov.
Att få sådana här varningsrutor med välskrivna felmeddelanden kan ge känslan av att mjukvaran ”vet” saker. Är den AI nu? Den hindrar verksamheten från att lagra tillstånd en närvarande människa annars skulle satt stopp för.
Every time we figure out a piece of it, it stops being magical; we say, ’Oh, that’s just a computation.’
Rodney Brooks (AI effect)
När blir mjukvaran intelligent?
Försäkringskassans system som är exponerade till den allmänna befolkningen klarar inte av att detektera när den senare föräldern råkar logga ledighet på samma dag som den andra föräldern redan registrerat. Istället ringer handläggare upp dagar senare och undrar hur det skall vara och hur de skall ändra inmatningen. Här skulle simpel validering med en popup när den senare registreringen görs som säger ”Din sambo/partner/fru/bättre hälft har redan registrerat ledighet på datum x, y, z. Vill du ändå spara?”.
”Bolagsverket tar emot vilket skräp som helst”
Jens Nylander
Den tidigare mp3-spela importören Jens ”Jens of Sweden” Nylander säger att han med AI (han vet vad han skall säga) hittar otaliga årsredovisningar som är rent felaktiga och motsägelsefulla. Sådant som aldrig borde tagits emot. Sådant som borde validerats vid sparningsstillfället.
Kontentan är att detta är enkel validering av invärden och det enda svåra att utföra är när och hur källan av dessa värden skall informeras om de felaktigheter som försöker lagras. De vanliga utmaningarna inom integration.
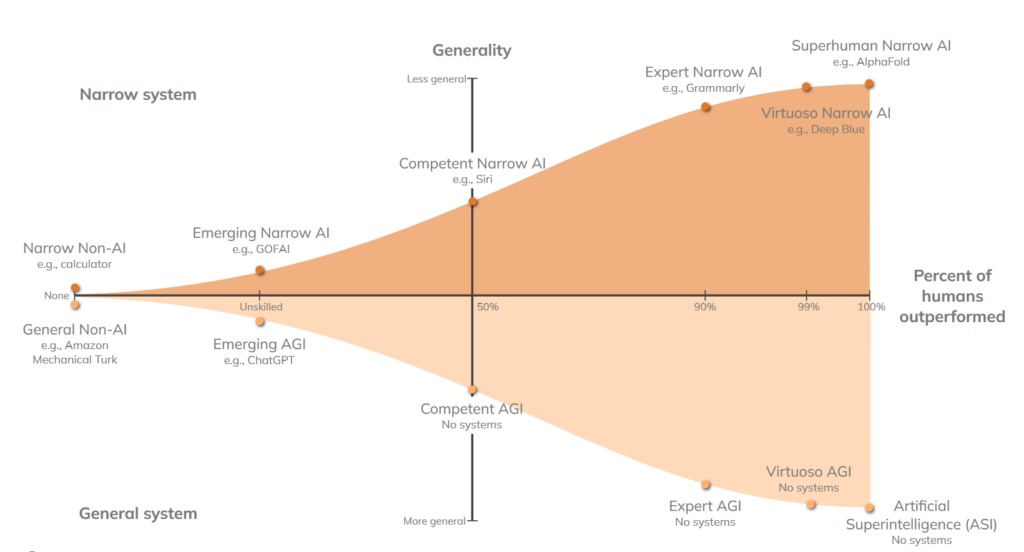
I grafen ovan hamnar applikationer längre åt höger när de slår större och större del av mänskligheten på den givna uppgiften. Där hittas redan schack och behandling av proteinstrukturer i den övre delen av grafen som står får applikationer som designats för enskilda uppgifter. I den nedre delen hittas stora språkmodeller (ChatGTP) som anses vara någon form av generell intelligens (vilket är oerhört häftigt!). Dock placeras de fortfarande långt till vänster då de är sämre än nästan alla människor på generella uppgifter. De är samtidigt oerhört kraftfulla i specifikt språkrelaterade uppgifter, där slår de säkert många.
Vad kan LLM då göra?
De ingår i samlingen av möjligheter som kallas ”Generative AI”. De är bäst på:
- Översätta
- Klassificera text
- Summera text
- Svara på frågor (Lagrad kunskap / RAG)
Där svara på frågor säkert är det mest hype finns. När modellerna blir tillräckligt stora visar det sig att de både lär sig språk samt av farten råkar lagra fakta om världen. Därför kan de konversera och svara på frågor men med risken att de, utan att veta det, genererar ”fakta” som inte är sant.
But roughly speaking (and today), you’re not asking some magical AI. You’re asking a human data labeler. Whose average essence was lossily distilled into statistical token tumblers that are LLMs. This can still be super useful of course. Example when you ask eg “top 10 sights in Amsterdam” or something, some hired data labeler probably saw a similar question at some point, researched it for 20 minutes using Google and Trip Advisor or something, came up with some list of 10, which literally then becomes the correct answer, training the AI to give that answer for that question.
För att motverka dessa hallucinationer behöver frågan kompletteras med någon form av RAG som tillför extra kunskaper till AI modellen vid frågetillfället.
But to deliver authoritative answers that cite sources, the model needs an assistant to do some research
Jag tror inte systemutvecklare kommer behöva på sikt grotta ner sig i RAG lösningar speciellt ofta utan de bästa verktygen kommer finnas inbyggda i exempelvis Sharepoint/Office eller Adobe reader. Kunskap i verksamhetsanpassade lösningar som använder fler än en modalitet lär vara mer troligt att behövas.
Kombination av modelltyper
Modeller med mer än en modalitet förstår hur en typ av data kan omvandlas till en annan typ. I bilden nedan använder jag modellen LLaVA till att föreslå ett filnamn till en bild som visar ett av de slitna fönster jag skall byta ut.
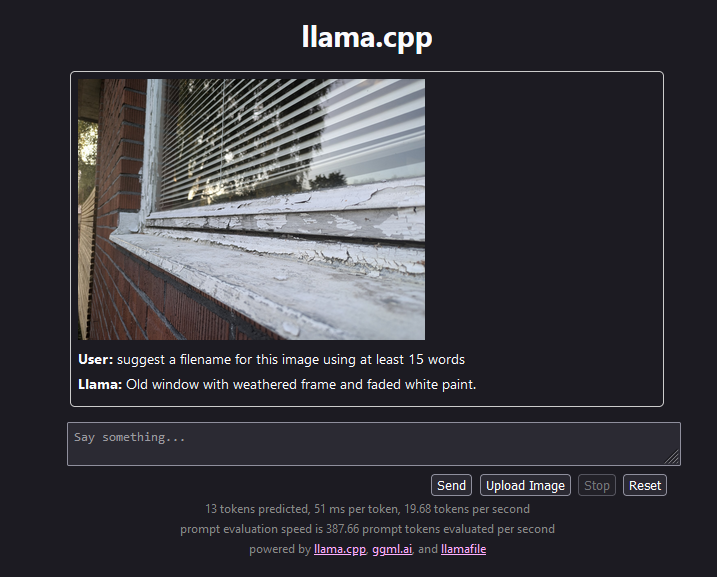
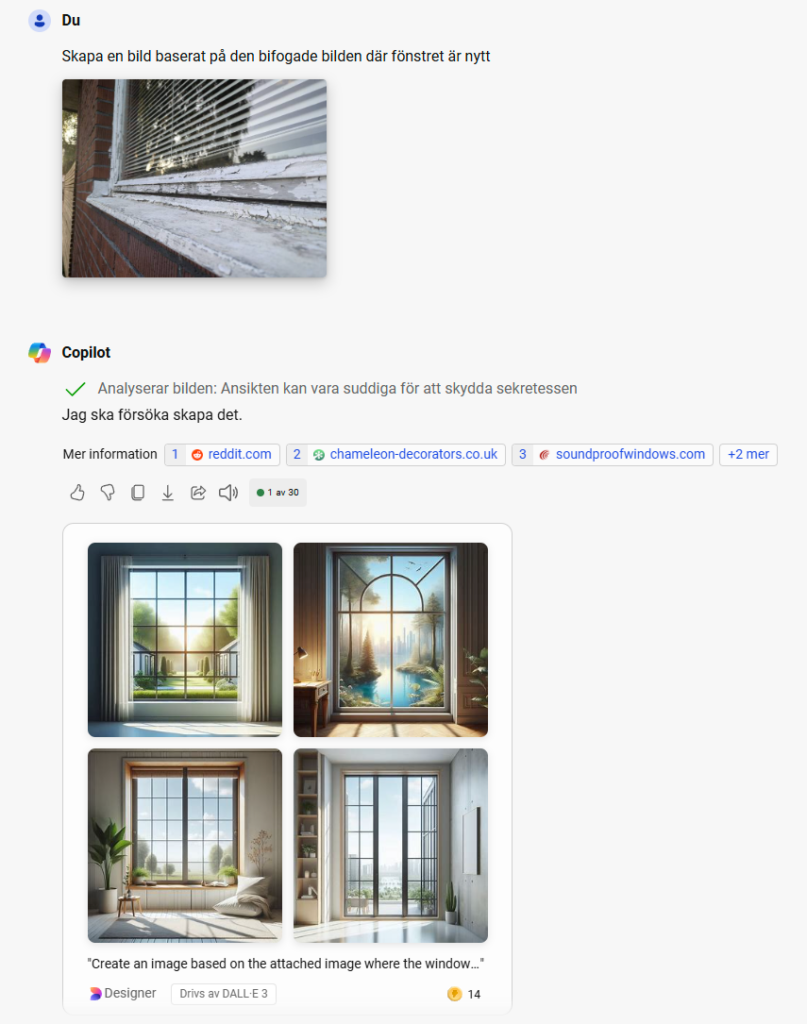
Med det fantastiska projektet llamafile går det snabbt köra en sådan modell på alla operativsystem. Dock har den inte möjligheten att skapa bilder så jag bad sedan Bing copilot att visa mig hur det kommer se ut med nya fönster:
Vart ger LLM mest nytta?
”Focus on concrete value. Discover whether you’re using generative AI or predictive AI. Determine a very specific, concrete, credible use case of exactly how this technology is going to improve some kind of operation in the enterprise and deliver value.”
Istället för att generera något till slutanvändaren kan språkmodeller redan i utvecklingsfasen skriva koden? Om de har tränats på stora mängder befintlig kod så klarar de absolut att generera kod som ser mycket bra ut. Min förhoppning är att sådana AI stödverktygen för utvecklare på sikt skall förstå semantiken i programmeringsspråket så de inte genererar saker som inte finns.
Används ett kompilerat språk har de stora utvecklingsmiljöerna sedan länge kunnat föreslå de nästa raderna kod som garanterat är giltiga då verktygen förstår det aktuella språket samt vilka variabler och funktioner som går att från den plats markören står.
Att skapa grundläggande formulär till CRUD appar som sparar och hämtar data från databaser lär AI baserade assistenter kunna göra utan problem oavsett språk och ramverk sett till den stora mängd exempel de måste lärt sig av under sin träning. Att tillsammans med utvecklarna nysta upp bästa sätt att förändra en befintlig stor kodbas där det mesta av den historiska kontexten av varför verksamhetens processer ser ut som de gör inte fångas av koden är nästa utmaning.